Nodejs学习
Nodejs学习
📚 Web 学习目录
🚀 HTML学习 - 📝 CSS学习 - 🔦 JavaScript学习 - 🎉 JavaScript 高级
本教程里的资料来源于网友的资料,自己整理以供学习。
Nodejs
什么是Node.js
- 基于谷歌ChromeV8引擎的JS运行环境(
不是框架不是库,而是一个可以不通过浏览器而解析JS语言的运行环境),Node中只有一些服务器操作级别API(如文件读写、网络服务构建、网络通信、http服务器等),没有BOM/DOM - Node是通过事件驱动、无阻塞输入输出模型而实现轻量和高效的
- Node生态包npm是世界上最大的开源库生态系统
Node.js可以做什么
- Web服务器后台
- 命令行工具(npm、git、hexo)
- 游戏服务器
npm
(node package manager: node包管理器)
package.json (包描述文件)
一个项目最好有一个package.json文件,可以保存你在开发过程中安装的包的信息
在安装包的时候 使用 npm install --save 包名 安装 即会自动将包名添加到package.json中,也可以通过npm init 初始化创建
如果移植项目,且有package.json文件,则可以直接执行npm install安装这些包
常用命令:
npm --version查看版本npm install --global npm升级npmnpm init生成package.json包npm init -y省略向导生成package.json包npm install 包名 (缩写: npm i 包名)安装包名(只下载)npm install 包名 --save (缩写: npm i-S 包名)下载并且保存为package.json文件中的依赖项npm i --save-dev中的dev代表这个包只是暂时使用,上线后即销毁不再使用用,在packjson文件里会保存在devDependencies项里,当我们转移项目使用npm install --production命令安装依赖包时会忽略devDependencies里的包npm uninstall 包名 (缩写: npm un 包名)卸载包(只删除,依旧保留依赖项)npm uninstall --save 包名 (缩写: npm un -S 包名)卸载包,同时删除依赖项npm help查看使用帮助npm 命令 --help查看该命令的使用帮助
如何利用Node.js解析js文件
创建编写js文件
1
console.log("Hello world")
输入 node +文件名 解析执行

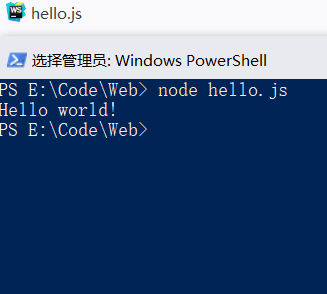
原生Node.js
Node.js中的JavaScript
包含四大部分:
- 即原本的ECMAScript
- node定义的核心模块,包含了很多服务器级别的API(如fs、url、http、os等)
- 第三方模块(通过npm下载的模块,如art-template)
- 用户自定义模块(自己创建的js文件)
模块的加载
语法:
require(模块名)require的作用:
执行外部模块中的语句
拿到被加载文件导出的接口对象
export(即核心模块的原理)
1 | //获取操作系统信息 |
require亦可引入自定义模块
1 | require('./test.js'); |
注意:
相对路径必须加
./可以忽略
后缀名node没有全局作用域,没有文档一说,只有模块作用域,一个js文件中的变量函数无法直接被外部引用,想引用只能通过export对象
利用require引用其他js文件中的变量函数
利用接口对象
exports或者module.exports
导出多个变量
exports.变量名 = xxx;module.exports.变量名 = xxx;1
2
3
4
5
6
7
8
9
10
11
12//b.js中的代码
var foo ='hello';
function add(x,y) {
return x+y;
}
exports.foo = foo;
exports.add = add;
// a.js中的代码
var b = require('./b.js'); //返回b.js中的export对象给bbianliang
console.log(b.foo +' world!'); //输出hello world!
console.log(b.add('hello','world')); //输出helloworld如果想直接导出一个变量,则必须用以下形式:
module.exports = 变量1
module.exports = [1,2,3,4];
这样引入这个模块时就
直接得到一个数组而不用对象的属性获取原理: 每个模块都有一个
module对象,里面存着exports对象,每个模块最后都默认返回module.exports,而直接使用的exports是对这个属性的引用,存储的是module.exports对象的地址,所以如果直接对exports直接赋值是无法改变module.exports的值的,只能在根本上改变,即直接改变module.exports的值
模块的加载顺序
模块会优先从缓存中加载,例如下面:
1 | //main.js |
结果:
1 | a.js has been loaded! |
解析: 结果不会出现两次b.js has been loaded!,因为a中已经加载过b了,所以不会再次执行,但是还是会取得其中接口对象,这样的优点是避免重复加载,提高效率。
三种模块的加载原理
用户自定义模块: 如果发现为路径形式的模块,则直接按照路径加载
./ :当前目录(文件操作可以忽略,自定义模块标识符必须有)
../ :上一级目录
/ : 当前文件所属磁盘根路径(C:/ D:/) 几乎不用
核心模块: 核心模块的本质也是文件,已经被编译到二进制文件中 按照名字加载即可
第三方模块: 凡是第三方模块都必须通过npm来下载,使用的时候通过
require('包名')的形式加载才可以使用
步骤:
如果判断不是为核心模块也不是路径形式,则会找当前文件所处目录下的
node_module目录下的同名目录中package.json中的main属性 main属性包含了入口模块 然后加载指向的文件如果
package.json文件不存在或者main指定的入口模块也没有 就会自动找目录下的index.js index.js为默认备选项如果以上所有都不成立则会进入上一级目录中的node_module目录查找
如果上一级还没有,则继续往上一级查找 直至报错
注意: 一个项目有且只能有一个node_module文件夹
fs文件操作模块
Nodejs有文件操作能力,通过引入文件系统模块,其中包含了各种文件操作API
读取文件
步骤:
首先用
require引入模块,需要什么功能,就引入什么模块,引入模块其实就相当于引入一些相关语法。操控文件则要引入file-system模块,用字符串fs表示1
var fs = require('fs');
利用fs模块的readFile方法读取文件
fs模块变量.readFile(文件地址,可选参数[编码格式],回调函数(error,data){})回调函数有两个参数,
第一个是读取发生错误时返回的错误对象,第二个是读取的数据,读取后的数据是二进制代码,可以在回调函数中将其转为字符串,JS中的转换成字符串的方法都能实现toStringString + ""、也可以传入第二个可选参数进行配置,读取后的文件会自动按照其值解码。如传入'utf8',则会按照utf8解码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15fs.readFile('write.txt',function(error,data){
if(error) {
console.log('读取文件失败');
} else {
console.log(data +'');
}
});
fs.readFile('write.txt','utf8',function(error,data){
if(error) {
console.log('读取文件失败');
} else {
console.log(data);
}
});
写入文件
步骤:
首先用require引入模块,需要什么功能,就引入什么模块,操控文件则要引入file-system模块,用字符串fs表示
1
var fs = require('fs');
使用fs模块的writeFile方法
fs模块变量.writeFile(文件地址,写入内容,回调函数(error){})回调函数有一个形参error,用于写入错误时返回错误信息
1
2
3
4
5
6
7fs.writeFile('./write.txt','hello world!!!!!',function(error){
if(error) {
console.log('写入失败'); // console.log(error);
} else {
console.log('写入成功!');
}
})
追加文件
fs.appendFile(文件地址,追加内容,回调函数(error){})
1 | fs.appendFile('t1.txt','这是写入的内容',(err)=>{ |
删除文件
s.unlink(文件地址,回调函数(error){})
1 | // 删除文件 |
读取文件列表
利用fs模块变量的readdir方法
fs.readdir(路径名,function(error,files) {})
回调函数的两个参数分别是错误对象以及读取到的文件名列表(数组形式)
1 | fs.readdir('./read.txt',function (error,files) { |
Http模块
Node.js中有http模块(字符串http表示)可以快速构建Web服务器
步骤
加载http模块
1
var http = require('http');
利用
http.createServe创建服务器实例1
var server = http.createServer();
设置request事件,当客户端发送请求时则触发该事件并调用其回调函数
服务器实例.on("request",回调函数(request,response){})回调函数中有两个参数
request和responserequestreq: 它表示一个正在进行的请求,可以获取一些请求信息,比如请求路径req.url: 返回请求路径req.headers: 打印全部请求头信息–对象形式req.method: 请求的方式
responseres: 可以给客户端发送响应信息res.setHeader(): 设置响应头,告诉客户端解码方式,如果响应的是html页面且html页面中元数据meta已经声明解码方式则可忽视res.statusCode: 设置状态码数字res.status.message: 设置状态码文字res.write(相应内容): 向客户端发送响应信息 write之后必须调用end方法用以告诉客户端已经输出完毕、可以有多句res.writeres.end(数据): 完成发送请求 必须跟在response.write之后 每个request事件只能有一句res.end也可以直接通过
response.end传送数据response.end(数据)支持字符串和二进制数据,会直接将二进制转为字符串
可以与request的url属性搭配使用实现不同请求传递不同信息
1
2
3
4
5
6
7
8
9server.on("request",function(request,response){
console.log('i got you');
if(request.url == '/haha') {
response.write('haha'); //如果请求的是haha地址,则页面显示haha
response.end(); //结束响应
} else {
response.end('please go to /haha'); //如果请求的不是haha地址,则会显示左边内容
}
})也可以传送文件数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30if(req.url == '/html') {
res.setHeader('Content-type','text/html;charset=utf-8');
fs.readFile('./resource/index.html',function(error,data){
if(error) {
res.end('读取失败!');
} else {
// res.end支持字符串也支持二进制 所以不用转换
res.end(data);
}
});
} else if (req.url == '/plain') {
res.setHeader('Content-type','text/plain;charset=utf-8');
fs.readFile('./resource/index.txt',function(error,data){
if(error) {
res.end('读取失败!');
} else {
res.end(data);
}
})
} else if (req.url == '/img') {
// 图片的MIME类型为image/jpg 一般可以不用设定
res.setHeader('Content-type','image/jpg;charset=utf-8');
fs.readFile('./resource/82710.jpg',function(error,data){
if(error) {
res.end('读取失败!');
} else {
res.end(data);
}
})
}注意:
response.end方法支持传送二进制数据,所以不用转化获取的文件数据就可以直接发送使用
listen方法绑定端口号,并启动服务器对其监听,启动后调用其回调函数服务器实例.listen(端口号,回调函数)1
2
3server.listen(3000,function(){
console.log('服务器启动成功 可以通过 http://127.0.0.1:3000 访问');
});//启动成功后,node环境中则会输出上面语句在node环境中打开该js文件,启动服务器(node环境中
ctrl+c可以关闭服务器
http的重定向
res.statusCode = 302;
res.statusCode: 此属性控制在刷新标头时将发送到客户端的状态代码
res.setHeader('Location',路径)
res.end()
URL模块
url模块可以对url地址进行一些操作
加载模块
1 | var url = require('url') |
解析地址方法
1 | url.parse('http://www.baidu.com',布尔值) |
返回地址的详细信息
其中第二个参数如果为true,则会将地址中的query参数转为对象,默认为false
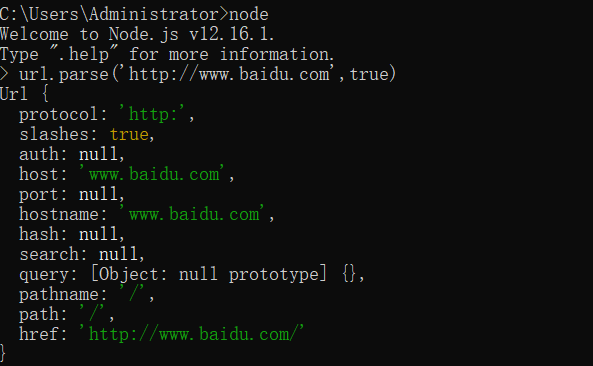
pathname: 返回路径
query: 返回参数
Path模块
可以对路径进行操作,注意不是操作URL
加载方式
1 | var path = require('path') |
模块方法
path.basename(路径): 获取路径中最后的文件名1
path.basename('c://a/b/c/index.js','.js') //返回'index'
parse.dirname: 获取路径中的目录部分1
path.dirname('c://a/b/c/index.js') //返回'c://a/b/c'
parse.extname: 获取路径中文件的扩展名1
path.extname('c://a/b/c/index.js') //返回.js
path.join(路径1,路径2): 将路径拼接起来1
path.join('c://a/b/c','index.js') //返回'c://a/b/c/index.js'
path.parse(路径): 将路径里的元素分别提取出来1
path.parse('c://a/b/c/index.js');
Node中的dirname和__filename
node中除了require、exports等相关模块之外,还有两个特殊的成员
__dirname: 可以获取当前文件所属目录的绝对路径__filename: 可以获取当前文件的绝对路径
注意:
文件操作中的
./是相对于执行终端的路径的目录而不是当前文件的目录,如果在别的路径下打开终端执行该文件则会找不到要读取的文件,所以在写文件路径时一般使用path模块的path.join将__dirname和文件拼接起来在大部分文件操作路径中一般都是用绝对路径,而为了防止项目移植时绝对路径失效,所以应该使用动态的绝对路径,也就是
dirname和filename模块加载中的
./则不受影响,是相对于当前文件的目录,不需要使用dirname和filename
art-template模板引擎模块
步骤:
加载模板引擎模块并赋予某个变量
1
var template = require('art-template');
注意:
下载的模板叫什么名字就加载时就填什么名字使用模板引擎的
netder方法template.netder(字符串,填充对象):返回的是填充后的字符串可以只写第一个参数快速返回一个页面,但是如果页面里有待填充的script标签则不能以这种方式发送,因为会被填充掉
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var ret = template.netder('hello {{name}}',{name:'bruce'});
//or
var str = `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Document</title>
</head>
<body>
大家好 我叫 {{name}}, 我今年 {{age}} 岁了,我来自 {{province}} ,我喜欢 {{each hobbies}{{$value}} {{/each}}
</body>
</html>`;
var ret = template.netder(str,{name:'bruce',age:29,province:'guangdong',hobbies:['dance','sing','rap','basketball']});如果要填充的是外部的文件,则读取文件后要记得将其转为字符串
1
2
3
4
5
6
7
8
9
10
11var fs = require('fs');
var content = {name:'bruce',age:29,province:'guangdong',hobbies:['dance','sing','rap','basketball']};
fs.readFile('template.html',function(error,data){
if(error) {
console.log('404 not found');
}
data = data.toString();
var ret = template.netder(data,content);
console.log(ret);
})配合
http模块使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19var http = require('http');
var server = http.createServer();
server.on('request',function(req,res) {
if(req.url === '/template') {
fs.readFile('template.html',function(error,data){
if(error) {
console.log('404 not found');
}
data = data.toString();
var ret = template.netder(data,content);
res.end(ret);
})
}
})
server.listen('3000',function(){
console.log('running...');
})
formidable模块实现文件上传
利用formidable第三方模块可以实现文件的上传
使用步骤:
安装
1
npm i --S formidable
加载
1
var formidable = require('formidable');
路由监听配置
先创建一个form对象用以接收文件
1
var form = new formidable.IncomingForm()
进行配置(可选)
form.encoding = "utf-8": 设置文件解码方式form.uploadDir = __dirname + '/img': 设置上传文件存放位置form.keepExtensions = true;: 设置文件是否保留后缀名form.multiples = true;: 设置是否为多个文件,如果为true,则files参数会以数组显示对文件解析并用回调函数进行操作
1
form.parse(req,function(err,fields,files){}
文件解析后,文件信息解析完成后会挂载到req上,文本的信息将挂载到fileds上,文件的信息将挂载到files上面(包括存放的绝对地址、文件大小、文件名字、文件mime类型)。
1
2
3
4
5
6
7
8
9
10
11app.post('/files',function(req,res) {
var form = new formidable.IncomingForm();
form.keepExtensions = true;
form.multiples = true;
console.log(form.type);
form.uploadDir = path.join(__dirname,"/img");
form.parse(req, function(err, fields, files) {
res.setHeader('Content-type','text/plain;charset=utf8');
res.end(JSON.stringify({fields,files}))
});
})
客户端渲染数据和服务端渲染数据的区别
客户端渲染(SPA:single page application): 用户通过地址栏或者链接标签进入一个新的链接后,向服务器
发出请求,服务器直接根据链接返回一个html页面(没有数据),页面中的数据渲染则是由页面中的ajax完成,ajax再次向服务器发出请求数据的请求,然后对页面进行渲染简单理解即浏览器发送页面请求,服务器返回的是一个模板页面,浏览器从上至下解析过程中需要发送ajax请求获取数据,最后再调用模板引擎(art-template等)渲染HTML结构,并把渲染后的结果添加到页面指定容器中。
服务端渲染(SSR:server side netdering): 用户通过地址栏或者链接进入一个服务器所监听的服务器的路径,服务器则根据
该路径返回一个页面(有数据),页面的数据渲染在服务器内由服务器完成,客户端只需要发送一次请求,不用ajax以Node为例,就是服务器根据请求
req.url读取对应html页面,将其转为字符串,再利用模板引擎将从数据库读取到数据渲染到页面中的某个结构中,再将这个字符串用res.end()发送出去
如何区分两者?
服务端渲染的页面数据可以通过浏览器审查元素看到。而客户端无法看到。
两者本质的区别?
客户端渲染和服务器端渲染的最重要的区别就是究竟是谁来完成html文件的完整拼接,如果是在服务器端完成的,然后返回给客户端,就是服务器端渲染,而如果是前端做了更多的工作完成了html的拼接,则就是客户端渲染。
服务器端渲染的优缺点是?
优点:
- 前端耗时少。因为后端拼接完了html,浏览器只需要直接渲染出来。
- 有利于SEO。因为在后端有完整的html页面,所以爬虫更容易爬取获得信息,更有利于SEO。
- 无需占用客户端资源。即解析模板的工作完全交由后端来做,客户端只要解析标准的html页面即可,这样对于客户端的资源占用更少,尤其是移动端,也可以更省电。
- 后端生成静态化文件。即生成缓存片段,这样就可以减少数据库查询浪费的时间了,且对于数据变化不大的页面非常高效 。
缺点:
- 不利于前后端分离,开发效率低。使用服务器端渲染,则无法进行分工合作,则对于前端复杂度高的项目,不利于项目高效开发。另外,如果是服务器端渲染,则前端一般就是写一个静态html文件,然后后端再修改为模板,这样是非常低效的,并且还常常需要前后端共同完成修改的动作; 或者是前端直接完成html模板,然后交由后端。另外,如果后端改了模板,前端还需要根据改动的模板再调节css,这样使得前后端联调的时间增加。
- 占用服务器端资源。即服务器端完成html模板的解析,如果请求较多,会对服务器造成一定的访问压力。而如果使用前端渲染,就是把这些解析的压力分摊了前端,而这里确实完全交给了一个服务器。
客户端渲染的优缺点是?
优点:
- 前后端分离。前端专注于前端UI,后端专注于api开发,且前端有更多的选择性,而不需要遵循后端特定的模板。
- 体验更好。比如,我们将网站做成SPA或者部分内容做成SPA,这样,尤其是移动端,可以使体验更接近于原生app。
缺点:
- 前端响应较慢。如果是客户端渲染,前端还要进行拼接字符串的过程,需要耗费额外的时间,不如服务器端渲染速度快。
- 不利于SEO。目前比如百度、谷歌的爬虫对于SPA都是不认的,只是记录了一个页面,所以SEO很差。因为服务器端可能没有保存完整的html,而是前端通过js进行dom的拼接,那么爬虫无法爬取信息。 除非搜索引擎的seo可以增加对于JavaScript的爬取能力,这才能保证seo。
REPL(read eval print loop)
代表一个快速的检测API的方法
在命令行中输入node,回车就可以直接执行js代码进行一些node的api的测试
Express框架的使用
Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具。
使用 Express 可以快速地搭建一个完整功能的网站。
安装
1
npm install --save express
加载包
1
var express = require('express');
创建服务器
var 变量 = express()相当于
var server = http.createServer()1
var app = express();
两种路由
接收get方式
app.get(path,function(req,res){})当服务器收到get请求路径
path(第一个参数)的时候,触发事件 相当于server.on('request',function(req,res))以及其中地址判断的封装第一个参数可以是具体的路径、路径模式、正则表达式的路径模式、以及这三者集合起来的数组
1
2
3
4app.get('/',function(req,res){
res.send('hello express!');
res.send(req.query);
})注意: 使用
res.send发送会自动解码不需要设置响应头,可以通过req.query属性快速获取get方式提交的参数接收post方式
app.post(path,function(req,res){})
监听
app.listen(端口号,function(){})1
2
3app.listen(3000,function(){
console.log('app is running at port 3000.')
})
express的中间件概念
中间件就是http请求和服务器响应之间对请求的处理函数,通过中间件,可以对数据进行操作使得我们能方便地操作请求数据编写服务器响应。如body-parse中间件对post请求的参数进行处理让我们可以通过res.body快速获取请求参数,express-session中间件可以让我们对数据进行保存,express.static是express内置中间件,可以让我们快速处理静态资源,express.Router路由中间件等等
Express中,对中间进行了几种分类:
- 不关心请求路径和请求方法的中间件,通过
app.use函数实现
app.use(function(req,res,next){})
客户端发起的任意请求都会经过这个中间件函数进行处理
next指下一个满足路径条件的中间件,如果有执行next,那么这个中间件执行完后就会执行下一个满足条件的中间件,如果没有next,就会忽略后面所有中间件
1 | app.use(function(req,res,next) { |
关心请求路径的中间件,通过app.use函数实现
app.use(路径,function(req,res,next){})客户端发起的以第一个参数开头的路径才会进入该中间件
严格匹配路径的中间件,通过
app.get/app.post等实现
中间件的执行机制
中间件的第一次执行是同步的,当一个请求发出到达服务器后,则按照顺序匹配所有中间件,当找到一个匹配时,则进入该中间件
如果该中间件最后没有执行next函数,则该请求在此中间件终止,如果有,则会直接进入后面匹配的中间件中(不是按顺序!)
重复1-2步
所以,对于一些封装请求数据方便我们操作以及处理静态资源的中间件我们应该放在路由之前编写,否则在编写路由时就无法使用封装好的数据。而对于404页面应该放在所有中间件后面,这样无法找到的页面则会返回404页面
中间件日志
通过无路径中间件来写入每一次http请求到日志中
1 | app.use((req,res,next) => { |
错误日志中间件
利用
try...catch...捕获路由解析中发生的错误,将其写入错误日志1
2
3
4
5
6
7
8app.get('/',(req,res) => {
try {
const msg = JSON.parse({'abc'});
res.json(msg);
} catch(e) {
console.log(e.message);
}
})访问日志和错误日志都可以写成单独一个中间件保存到数据库中
错误收集统一处理中间件
中间件回调函数参数如果是四个,第一个就是前面中间件中next返回的错误对象
注意: 一定要四个参数 才能正确接收错误对象
1
2
3
4
5
6
7
8
9
10
11
12app.use((err,req,res,next) => {
const error_log = `
错误名:${err.name}
错误信息:${err.message}
错误堆栈:${err.stack}
错误时间:${new Date()}
`
fs.appendFile('./err_log.txt',error_log,err => {
res.writeHead(500,{});
res.end('500 服务器正忙,请稍后重试');
})
})
express快速处理静态资源(使用express.static中间件)
express.static(root,[选项]): 该root参数指定要从其提供静态资产的根目录。该功能通过req.url与提供的root目录结合来确定要提供的文件。当找不到文件时,它不会发送404响应,而是调用next()继续前进到下一个中间件,从而允许堆栈和回退。
express.use(以什么路径开头,express.static(公开的资源的目录))
当以/public开头时,去路径./public/目录中找对应的资源
1 | app.use('/public',express.static('./public/')); |
必须是/a/public目录中的资源路径 即以a代替了public
1 | app.use('/a/',express.static('./public/')); |
如果没有第一个参数,则可以通过省略/public的方式来访问其中资源 即直接输入其中文件路径名就可以访问 不能添加public
1 | app.use(express.static('./public/')); |
express中模板引擎的使用
安装模块
1
2npm install --save art-template
npm install --save express-art-template配置(配置该选项之后
res.netder方法就可以用了)server.engine(ext,回调): 将给定的模板引擎注册callback为ext。server.engine(模板文件后缀名,加载express-art--template包)1
2var server = express();
server.engine('html',require('express-art-template'));渲染
res.netder('模板名',数据对象): 渲染模板并发送1
2
3server.get('/',function(req,res) {
res.netder('index.html',{comments:comments});
})注意: 第一个参数不能写路径 应该直接写文件名 默认会去项目中的views目录中查找 文件名必须以配置时第一个参数为后缀
express中的重定向
res.redirect(路径)
1 | server.get('/pinglun',function(req,res) { |
express中的发送文件
res.sendFile(absolutePath): 路径必须为绝对路径
1 | server.get('/',function(req,res) { |
express中读取post主体(req.query只能获取get方式的数据)
安装
下载
body-parser中间件1
npm install body-parser
加载
1
var bodyparser = require('body-parser')
配置
接收两种格式的数据
app.use(bodyparser.urlencoded())app.use(bodyparser.json())使用
在路由中用res的属性body获取即可(返回对象)
res.body1
2
3app.post('/pinglun',function(req,res){
console.log(res.body);
})
express中的router中间件
在express中可以通过express最高级对象的Router方法生成一个router对象,router对象是一个隔离的中间价,不属于任何http对象,可以对其进行路由配置(get/post等)。可以通过app.use(router对象)将其作为一个应用赋予http对象
1 | var express = require('express'); |
该特性可以让我们进行模块化开发,将入口文件和路由文件分开,路由文件将创建好的router对象通过exports.module导出,入口文件加载路有文件获取并使用use函数即可
express中的session中间件
session就是会话,会话是一个比连接粒度更大的概念,一次会话可能包含多次连接,每次连接都被认为是会话的一次操作。
session 的技术实现上: 会对每一次对话产生一个唯一的标识id进行标识。将数据存在该id下就可以实现状态的保存
session生命周期: 当用户在Web页面之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去,如果会话关掉(客户端关掉),那么就消失
当用户请求来自应用程序的 Web 页面时,如果该用户还没有会话,则 Web 服务器将自动创建一个 Session 对象。当会话过期或被放弃后,服务器将终止该会话。在Exrpess中,默认不支持Session和Cookie,可以使用第三方中间件: express-session来解决
步骤:
安装
1
npm install express-session
配置 一定要在app.use(router)之前
1
2
3
4
5app.use(session({
secret:'keyboard cat', //配置加密字符串,会在原有加密基础上和这个字符串拼接起来加密,增加安全性
resave:false,
saveUninitialized:true //无论是否使用session都默认给客户端一把钥匙
}))使用
可以通过
req.session来访问和设置Session数据添加Session数据:
req.session.foo = 'bar'访问Session数据:
req.session.foo
插件说明
Nodemon插件: 可以自动重启服务器,不用每次修改js后手动重启
安装:
1 | npm install --save-dev nodemon |
使用:
1 | nodemon 文件.js |
Node中使用MongoDB数据库
可以使用官方的mongdb包来操作,也可以使用第三方mongoose包
MongoDB的数据结构
可以如下面理解:
1 | 一个数据库test:{ |
下面以mongoose为例
创建集合
加载包
变量名 = require('mongoose');1
const mongoose = require('mongoose');
连接到一个数据库
mongoose.connect(mongodb://域名/数据库名)1
mongoose.connect('mongodb://localhost/zykj');
设计集合结构
获取一个Schema构造函数用以创建结构对象
变量名 = mongoose.Schema1
var Schema = mongoose.Schema;
构造结构
var 结构名 = new Schema(文档结构)1
var blogSchema = new Schema({ title: String, author:String, body:String })
即创建了一个名为blogSchema的文档结构
发布模型(创建一个集合对象)
mongoose.model: 将一个架构发布为model 也就是创建了一个集合,第一个参数为集合的名字,第二个参数为这个新建集合存储的文档的格式(大写会转为小写,在后面会加s) 返回一个构造函数1
var User = mongoose.model('User',blogSchema);
返回一个构造函数用以创建新文档,此时数据库中已有名为users的集合,该集合的文档结构就是blogSchema的对象的结构,但还没有数据
数据操作
新增数据
new创建一个模型的实例对象即可,数据结构按照设置好的Schema模板来
1
var art1 = new User({ title:'how to kill you', author:'bruce chen', body:'just use fucking pencil!' })
持久化存储: 将创建好的User对象调用
save方法即可 可传入回调函数1
2
3
4
5
6
7art1.save(function(err) {
if(err) {
console.log(err);
} else {
console.log('保存成功!');
}
});查询数据
查询全部
调用模型对象的
find方法: 参数为回调函数,函数的参数第一个是错误对象,第二个查询结果结果都包裹在数组中User.find(function(err,data){})1
2
3
4
5
6
7User.find(function(err,data) {
if(err) {
console.log(err);
} else {
console.log(data);
}
})按条件查询
依旧是find方法:
第一个参数是数组形式的查询条件,第二个为查询完成后的回调函数,返回数组形式,返回多个符合条件的文档User.find({条件},function(err,data){})1
2
3
4
5
6
7User.find({author:'bruce huang'},function(err,data) {
if(err) {
console.log(err);
} else {
console.log(data);
}
})查找符合条件的第一个
findOne方法:按照条件查找第一个符合条件的文档 返回对象形式User.findOne({条件},function(err,data){})1
2
3
4
5
6
7User.findOne({author:'bruce huang'},function(err,data) {
if(err) {
console.log(err);
} else {
console.log(data);
}
})注意: 用find方法查找数据时,即使数据为空,也会返回一个空数组,所以判定应当判定长度而不是变量
删除数据
利用模型的remove方法
User.remove(条件,回调函数(错误对象,返回结果))1
2
3
4
5
6
7User.remove({author:'bruce huang'},function(err,data) {
if(err) {
console.log(err);
} else {
console.log(data);
}
})更改数据
利用模型对象的
User.findByIdAndUpdate(id值,修改的值(对象形式),回调函数)1
2
3
4
5
6
7User.findByIdAndUpdate('5dc5583de916d516a8577746',{'body':'not pencil'},function(err,data) {
if(err) {
console.log(err);
} else {
console.log(data);
}
})注意: 当用数据库读取到的_id数据渲染页面时,页面中应该写成id,不要写_id
分段读取数据
mongoose.find().skip(n).limit(n).exec((err,data) => {})skip(n): 代表跳过n条数据limit(n): 代表只读取n条数据exec回调函数的第二个参数data代表读取到的内容
一般用于页面分页的处理,可以配合
twb-pagination使用
关于异步编程(回调地狱、promise)
什么是回调地狱?
当有多个异步事件时,其输出结果顺序是不定的,一般取决于文件大小。如下面代码
1 | fs.readFile('./data/a.txt','utf8',function(err,data) { |
所以为了让事件按照我们想要的顺序生成结果,我们可以将后执行的事件嵌入先执行的事件的回调函数里,如下面代码
1 | fs.readFile('./data/c.txt','utf8',function(err,data) { |
但是如果事件太多,那么代码就会太冗长,难以维护,形成了回调地狱
解决这个问题,我们可以使用ES6新增语法Promise
表单的同步提交(默认)和异步提交(ajax)
表单具有默认的提交行为,默认是同步的,同步表单提交,浏览器会锁死(转圈儿)等待服务端的响应结果。表单的同步提交之后,无论服务端响应的是什么,都会直接把响应的结果覆盖掉当前页面。
后来有人想到了一种办法,来解决这个问题。即提交表达后在服务器重定位到相同的页面,通过模板引擎将要提示的信息渲染到页面上(现在仍有网站使用这种方式)
再后来出现了ajax,实现不用刷新页面也能获取服务器发送的数据的效果
Node中Babel转码器的部署
虽然现在浏览器对ES6的支持性普遍很好,但是考虑到一些旧版浏览器用户以及我们可能会想通过es6模块语法实现模块化开发,所以我们需要babel转码器将我们写的es6代码转为浏览器普遍支持的代码以便于开发和上线
部署Babel的第一步
Babel 的配置文件是.babelrc,存放在项目的根目录下。使用 Babel 的第一步,就是配置这个文件。
该文件用来设置转码规则和插件,基本格式如下:
1 | { |
其中present字段设定转码规则,可以通过以下代码下载转码规则:
1 | ## 最新转码规则 |
dev的含义: 代表这个包是开发临时使用,保存到 package.json 文件中的 devDependencies 选项中。
注意: .babelrc文件的配置必不可少
@babel/regitser模块
开发的过程中,需要不断的调试,为了方便,我们需要能实时转码的工具,即每次调用都不需要一个文件一个文件的转码,可以用@babel/regitser模块
使用方法:
先安装该模块
1
npm install --save-dev @babel/register
设立一个入口文件,该文件用于载入
babel/register模块并将其中require的js文件进行实时转码1
2
3// index.js
require('@babel/register');
require('./es6.js');注意: 必须
先引入模块再引入要实时转码的文件每当调试时,运行该入口文件即可
1
node index.js
注意: 该模块只用适合在开发环境使用,用于开发调试时将源代码转换。因为是实时的,如果用于上线后,会影响网站性能
@babel/cli
当完成开发后,我们需要将写好的代码完全转码成新的文件用于线上环境,babel/cli工具可以帮助完成。
这个模块用于命令行中转码使用,可以将js文件代码转码输出到命令行中也可以转码输出到新的文件里,还可以转码整个目录的文件到另一个目录
使用方法:
安装
1
npm install --save-dev @babel/cli
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14## 转码结果输出到标准输出
npx babel example.js
## 转码结果写入一个文件
## --out-file 或 -o 参数指定输出文件
npx babel example.js --out-file compiled.js
## 或者
npx babel example.js -o compiled.js
## 整个目录转码
## --out-dir 或 -d 参数指定输出目录
npx babel src --out-dir lib
## 或者
npx babel src -d lib所以可以使用
babel src -d lib将src目录下的代码转码生成同名文件并放到lib文件夹中。注意: src是我们开发时写的代码,有es6语法。lib是上线时使用的代码,无es6语法
packagejson文件中script字段用法
1 | { |
script字段用于设置快捷命令执行,即可以通过指定的新命令来执行某些命令
1 | script:{ |
命令名可以随意起(除了start和prestart),执行方式为npm run 命令名
比如可以将调试时执行入口函数的命令其名为’dev’
1 | "build": "babel demo1.js", |
start命令用于执行上线时所使用的入口函数,prestart的命令会在执行start前自动执行,所以可以用来执行babel/cli工具先将源代码转为上线时所用代码
1 | "prestart": "babel src -d dist", |
所以只要将babel/cli安装在项目中并且babel src -d lib写入script的prestart字段就可以保证每次执行npm run start前都会被转码
项目的模块化
dist文件: 用于存放转码后的源代码,用于上线src文件: 用于存放开发过程中的源代码,一般还可以根据不同业务分为不同的文件夹,如路由文件夹、中间件文件夹、数据处理函数文件夹、数据库模型文件夹views文件夹: 用于存放页面文件,根据页面不同分成多个子文件夹public文件夹: 存放公共文件的文件夹,比如图片、css文件、js文件等
NVM
(Node Version Management)node版本管理工具
nvm list: 查看所有已安装的 node 版本nvm install 版本号: 安装指定版本的 nodenvm use 版本号: 切换到指定版本号nvm proxy 代理地址: 配置代理进行下载
- 支付宝
- 微信

